



做运维这些年,我越来越认同一句话:真正让业务稳定运行的,不只是服务器配置有多高,也不是带宽有多大,而是你能不能在问题发生前看见风险,在问题出现时迅速定位,在业务恢复后形成闭环。过去三个月,我把日常业务的监控体系逐步切换和完善到阿里云生态里,最直接的感受就是,稳定和省心并不是一句宣传语,而是被一套完整能力慢慢托起来的。
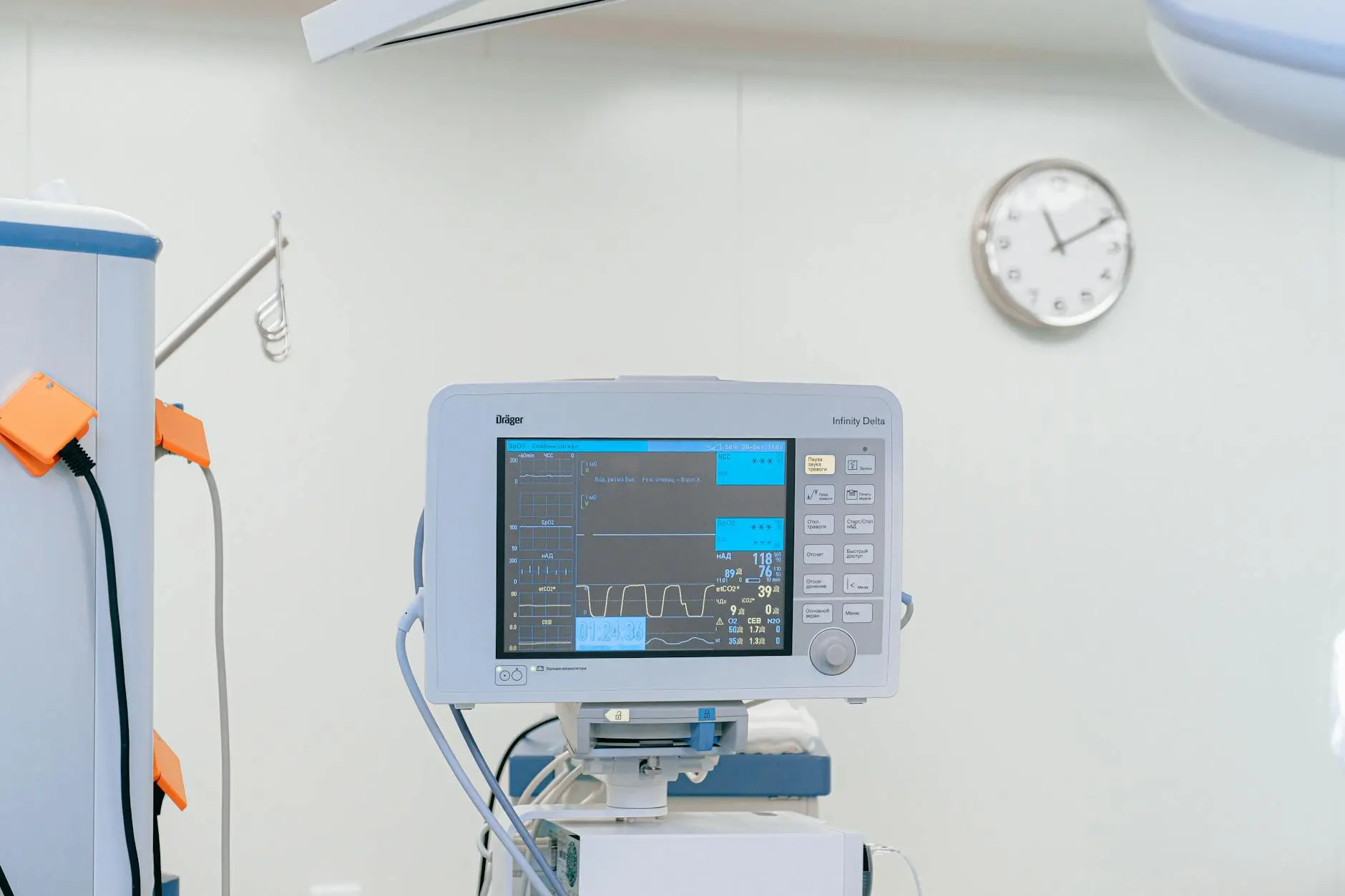
很多团队一开始并不重视监控,尤其是业务刚起步的时候,大家更关心上线速度、功能迭代和获客成本。等到流量突然上来,或者某次活动期间出现接口超时、CPU飙升、数据库连接数打满,才意识到没有监控几乎等于“闭眼开车”。我之前接手过一个内容平台,业务量不算夸张,但架构已经涉及多台ECS、RDS、负载均衡和对象存储。最初他们靠人工查看机器状态,偶尔用脚本发告警,平时似乎还能维持,一旦夜间出现异常,就很容易错过最佳处理窗口。
真正让我开始重视云监控阿里这套能力,是一次看似普通的接口抖动。当时某个推荐服务的响应时间在十几分钟内持续升高,但应用层日志并没有立刻暴露明显错误。若按照以前的方式,大家只能登录服务器一台台排查。后来依靠阿里云监控提供的多维指标,我们很快发现并不是应用代码本身异常,而是某个节点磁盘I/O等待时间明显上升,进而拖慢了缓存文件读写。这个定位过程比过去快了很多,也让我第一次感受到,监控的价值不只是“报错”,更是帮助团队建立对系统运行状态的全局认知。
用这三个月时间来看,阿里云监控最打动我的地方,首先是它和云上资源的关联非常自然。对运维来说,最怕的是监控工具和资源管理分离:机器在一个平台,日志在一个平台,告警在另一个平台,排查时来回切换,信息还不一定同步。阿里云监控在ECS、RDS、SLB、容器服务等资源上的指标接入相对顺畅,很多基础监控不需要花大量时间自己搭建。对中小团队尤其友好,因为你不必从零去铺设一整套复杂系统,就能先把CPU、内存、网络、磁盘、连接数、延迟等核心指标纳入观察范围。
但如果只是“看见数据”,那还称不上省心。真正决定体验好坏的,是告警机制是否有效。以前不少团队都有一个通病:监控项设了很多,消息也发了很多,结果大家被频繁打扰,最后反而对告警麻木。我的做法是在阿里云监控里分层配置规则,把系统级、应用级和业务级告警尽量区分开。比如CPU短时波动,不一定需要半夜叫醒值班同事;但数据库连接池持续逼近阈值、核心接口成功率下滑、负载均衡后端健康检查异常,这些就必须快速响应。经过几轮调整后,告警噪音明显下降,真正有价值的信息反而更容易被看见。
这里有一个很典型的案例。我们在一次促销活动前,对订单系统进行了压力测试,测试结果看起来不错,接口平均响应时间也在预期内。活动上线后,前两个小时整体平稳,但随后支付回调链路出现零星超时。若只看应用日志,会觉得问题并不集中,像是偶发网络波动。可结合阿里云监控的时间序列数据后,我们发现某时段内公网出口带宽并未打满,但内部几台应用实例的连接数上升曲线异常陡峭,而且实例之间不均衡。进一步排查后确认,是某次配置变更导致连接复用策略失效,让部分节点承受了额外压力。因为发现得早,团队在用户大量投诉前就完成了修复。这个过程让我意识到,监控不是故障后的“验尸工具”,而是业务运行中的“生命体征仪”。
除了故障处理,阿里云监控对容量规划也很有帮助。很多人把监控理解为“出了问题看一眼”,其实更大的价值在于趋势判断。三个月的持续观察,让我们对业务的峰值时段、资源消耗节奏和各类服务的瓶颈点有了更直观的认识。比如某类任务在每天凌晨集中运行,CPU会规律性上冲;某个接口在周末夜间访问量显著增加;数据库读写负载虽然总体平稳,但在活动预热期会提前两天抬头。这些规律如果只凭经验很容易模糊,但放到监控图表里就会非常清晰。也正因为有了这些数据,我们在扩容和降本之间做决策时更有底气,而不是一味“宁多勿少”。
说到降本,监控做得好,本身就是节约成本的一部分。很多企业在云上花费增加,并不完全是因为业务增长,也可能是资源配置长期粗放:不必要的高规格实例、长期空闲的带宽、被低效任务持续占用的计算资源。如果没有可靠的监控依据,优化往往停留在主观判断,既怕降配后出问题,又担心继续维持造成浪费。通过这段时间的观察,我们对部分非核心服务做了更合理的资源调整,把一些长时间低负载的实例下调规格,同时保留关键链路的弹性余量。结果是整体成本更可控,服务稳定性反而没有受影响。
我认为云监控阿里另一个值得肯定的地方,是它降低了团队协作中的沟通成本。开发、运维、测试甚至业务负责人,面对问题时最怕各说各话。有人说是代码导致的,有人说是数据库问题,还有人怀疑网络抖动。如果缺少统一的数据视图,排查过程很容易变成“凭感觉讨论”。有了较完整的监控面板后,很多争议可以快速落到事实层面:异常出现在哪个时间点、先升高的是延迟还是错误率、是否伴随资源使用异常、影响范围是单节点还是全局。这样一来,会议更短,定位更快,责任边界也更清晰。
当然,任何监控工具都不是装上就万事大吉。三个月使用下来,我最大的体会是,工具提供的是能力,真正决定效果的还是使用方法。比如阈值不能照搬默认值,要根据业务特点不断微调;比如不能只监控基础设施,还要逐步补上应用指标和关键业务指标;再比如告警通道和升级机制要清晰,否则消息发出来也未必有人及时处理。阿里云监控在底层能力上已经帮团队省掉了不少搭建和维护成本,但想把它用好,仍然需要结合自己的业务场景做长期建设。
如果让我用一句话总结这三个月的感受,那就是:稳定从来不是“没有故障”,而是有能力面对故障、预防故障,并持续优化系统。对经历过深夜排障的人来说,最珍贵的不是少点几次登录服务器,而是心里有数,知道系统当前状态怎样、风险在哪里、出了问题先看什么。阿里云监控给我的正是这种确定性。它未必总是最抢眼的部分,却像基础设施里的地基一样,平时不喧哗,关键时刻特别可靠。
如今很多企业上云已经不是选择题,而是在云上如何把业务做稳、做快、做精的问题。在这个过程中,监控不是附属品,而是运营质量的一部分。经过三个月的持续使用,我越来越觉得,想要真正做到稳定省心,离不开一套成熟、可落地、能和业务一起成长的监控体系。而在日常实践里,云监控阿里确实给了我不少信心:它不只是帮我看见问题,更帮团队减少焦虑、提升响应效率,并把稳定性建设从“被动救火”变成“主动经营”。这也是为什么我愿意说一句发自实际体验的话:用了三个月,真的离不开。
内容均以整理官方公开资料,价格可能随活动调整,请以购买页面显示为准,如涉侵权,请联系客服处理。
本文由星速云发布。发布者:星速云小编。禁止采集与转载行为,违者必究。出处:https://www.67wa.com/175387.html


